Worklog: Optimising GEMM on NVIDIA H100 for cuBLAS-like Performance (WIP)
Introduction
Matrix multiplication sits at the core of modern deep learning. Whether it is transformers, CNNs, or even simple MLPs, everything eventually reduces to GEMM. GPUs are built to run this operation at scale, and libraries like cuBLAS set the performance bar with kernels tuned down to the last instruction.
In this blog I am rebuilding that path from the ground up on the NVIDIA H100. I start with the most basic kernels and gradually layer on optimisations: tiling into shared memory, register blocking, vectorisation, warp tiling, and then Hopper-specific features such as tensor cores, the Tensor Memory Accelerator, and more. This project is inspired by the great work of Pranjal Shankhdhar and Simon Boehm, and I try to build on from there with my own contributions, exploring the full optimisation path while providing a consistent and reproducible repository for replicating results.
The goal is not just raw speed. It is to see what each change actually buys us, what the profiler tells us at every step, and how a kernel evolves from naive to highly tuned. By the end we will measure how close hand-rolled CUDA can get to cuBLAS, and whether on fixed matrix sizes we can even edge past it.
The full code is on my GitHub. All code is available on my GitHub with support for FP32 and BF16+FP32 mixed precision.
Let’s get started.
Kernel 1: Naive
In the CUDA programming model, computation is organised in a two level hierarchy. Each invocation of a CUDA kernel creates a new grid, which consists of multiple blocks. Inside each block there can be up to 1024 threads in total, regardless of whether the threads are arranged in 1D, 2D, or 3D. That is, the product . All threads in a grid execute the same kernel function, and they rely on thread indices to distinguish themselves and to identify the appropriate portion of the data to process In general, it is recommended that the number of threads in each dimension of a thread block be a multiple of 32 for hardware efficiency reasons. They align with another concept called warps, which we will introduce in the next kernel. For now, just remember that a warp is a group of 32 threads, so keeping dimensions consistent with that is beneficial.. Hence, CUDA programming is an instance of the single program multiple data parallel (SPMD) paradigm.
When a thread inside a kernel calls a device function, it executes the function itself. It only knows about the thread that called it. Basically, it is just a normal function like in C++, but happening inside one GPU thread — and you can imagine thousands of these function instances running in parallel.
global functions are the kernels. They are compiled for GPU execution but launched from the CPU (host). A kernel launch creates a grid of blocks, and each thread inside those blocks starts executing the kernel code independently.
All thread blocks operate on different parts of the input, so they can be executed in any arbitrary order. Therefore, we should never make assumptions about the execution order of blocks, or about which thread within a block will execute first.
Simon’s blog post gives a great visualisation of this thread hierarchy.
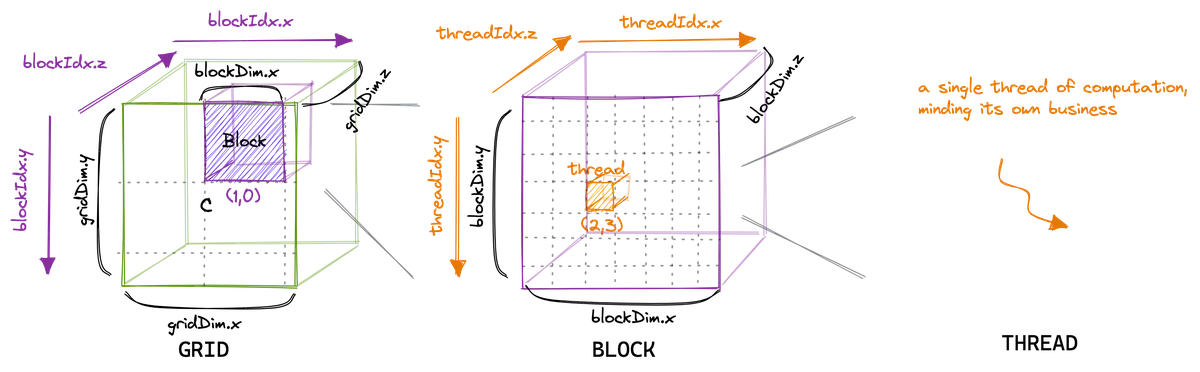
In this first kernel, we will assign each thread in a block (within the grid) to compute exactly one element of C. Each thread takes its own coordinates and loops through the corresponding row of A across the shared dimension N (I know most official resources use K for this, but I’ve already committed to N across all kernels, so I’ll stick with that for consistency). At the same time, the thread loops down the matching column of B, accumulating the products as it goes. Once the loop is done, the result is written back into C at the same coordinates.
Spoiler alert: doing this 1-1 mapping of thread result to output is not actually the most efficient (if you guessed that, you’re right). In later kernels, we will have a single thread compute multiple elements of the output, but let’s leave this for now.
Below is a simple visualisation of how this works, including an example from the perspective of a single thread.

The code for this kernel looks like this:
__global__ void gemm_naive_bf16(
const __nv_bfloat16* __restrict__ A,
const __nv_bfloat16* __restrict__ B,
__nv_bfloat16* __restrict__ C, int M,
int N, int K,
float alpha, float beta) {
uint row = blockIdx.y * blockDim.y + threadIdx.y;
uint column = blockIdx.x * blockDim.x + threadIdx.x;
if (row < M && column < K) {
float cumulative_sum = 0.0f;
for (int n = 0; n < N; n++) {
// Loop over shared dimension
cumulative_sum += __bfloat162float(A[row * N + n]) *
__bfloat162float(B[n * K + column]);
}
float c_old = __bfloat162float(C[row * K + column]);
C[row * K + column] =
__float2bfloat16_rn(alpha * cumulative_sum + beta * c_old);
}
}
Kernel 2 (Coalesced Naive) - Kernel 5 (2D Register Tiling)
Write up in progress. All code for kernels are available on GitHub.
Kernel 6: Vectorised 2D Register Tiling
The profiler shows the kernel is already making reasonably good use of our GPU, compute throughput sits around 66% of peak, memory throughput around 85%, and we’re hitting 56% of the device FP32 roofline.
Bare in mind cuBLAS sits at around 85%, and no practical workload would actually reach 100% of the hardware theoretical peak.
Looking carefully, there are some key metrics subtleties that are hurting our current performance and holding us back from achieving higher compute throughput.
Most critically, shared memory accesses show heavy bank conflicts: about 5-way conflicts on loads and 2.6-way conflicts on stores, with over 40% of all shared memory wavefronts wasted in serialisation.
In Nsight Compute, a wavefront refers to the hardware chunk of shared memory requests that can be handled in a single cycle. When bank conflicts occur, the request must split into multiple wavefronts, each processed one after the other, causing stalls.
We haven’t really considered bank conflicts yet in our kernels, so this is a suitable time to introduce the concept.

I tried to draw the shared memory organisation to visualise this better, but the key concept to grasp is that shared memory on NVIDIA GPUs (including H100) is divided into 32 banks, each of which can serve one 4-byte word per cycle. I like to think of it like thirty-two checkout lanes at a supermarket, with each lane handling one customer per cycle. A “word” here just means the basic unit of storage: 4 bytes (so a single float for ex).
The bank index can then be simply calculated using the common modulo trick:
bank_index = word_index % 32
- Bank 0: words 0, 32, 64, …
- Bank 1: words 1, 33, 65, …
- …
- Bank 31: words 31, 63, 95, …
Now, when a warp of 32 threads issues a shared memory access:
- If each thread touches a different bank → no conflict, everyone gets served in parallel. Good!
- If multiple threads try to read/write different addresses in the same bank → those requests are serialised, one after another. That’s a bank conflict.
- If all threads read the exact same word → the hardware does a broadcast instead, which is efficient. Also good!
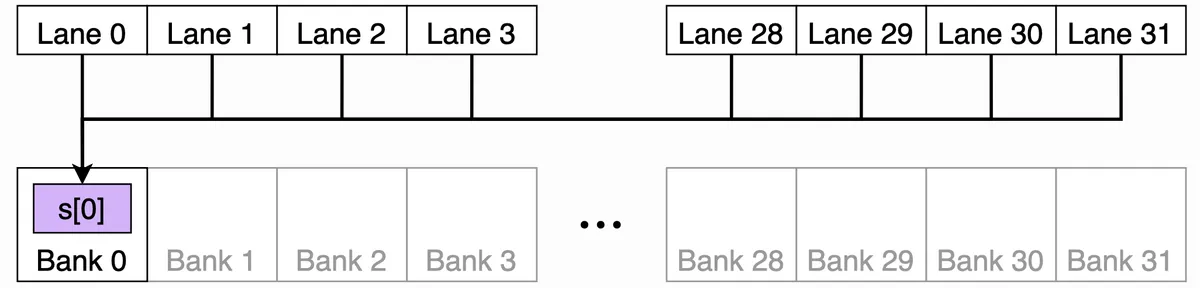 In this diagram, all 32 lanes can read from the same banked word.
The hardware broadcasts the value efficiently instead of causing a conflict.
In this diagram, all 32 lanes can read from the same banked word.
The hardware broadcasts the value efficiently instead of causing a conflict.

Let us start with the store conflicts. In our code the ≈ 2.6 conflicts on stores show up when we populate sharedA with the transposed tile.
// Populate smem using vector loads
float4 tempA = reinterpret_cast<const float4*>(&A[smem_ty_A * N + smem_tx_A*4])[0]; // [0] dereference issues one ld.global.nc.v4.f32
// Transpose A (instead of 128x8 previously for ex, now it will be 8x128)
sharedA[(smem_tx_A * 4 + 0) * TILE_SIZE_M + smem_ty_A] = tempA.x;
sharedA[(smem_tx_A * 4 + 1) * TILE_SIZE_M + smem_ty_A] = tempA.y;
sharedA[(smem_tx_A * 4 + 2) * TILE_SIZE_M + smem_ty_A] = tempA.z;
sharedA[(smem_tx_A * 4 + 3) * TILE_SIZE_M + smem_ty_A] = tempA.w;
ty ranges across rows and tx is either 0 or 1 (in this kernel configuration ofc). The word index for each scalar store is:
- word_index = (smem_tx_A*4 + q) * TILE_SIZE_M + smem_ty_A → q in {0,1,2,3}
- bank = word_index % 32
With TILE_SIZE_M = 128, the leading stride is divisible by 32 banks. Because 128 % 32 = 0, the bank depends only on the row part, not on the column part, so inside each half warp two lanes share the same smem_ty_A and both target the same bank for each of the four scalar stores. This is exactly the pattern the profiler called out as two way store conflicts.
One common trick to avoid this class of conflict when the leading stride is a multiple of 32 words is padding.
// Allocate shared memory. Use padded leading strides that keep float4 alignment
constexpr uint STRIDE_A = (TILE_SIZE_M % 32u == 0u) ? (TILE_SIZE_M + 4u) : TILE_SIZE_M;
constexpr uint STRIDE_B = (TILE_SIZE_K % 32u == 0u) ? (TILE_SIZE_K + 4u) : TILE_SIZE_K;
static_assert((STRIDE_A % 4u) == 0u, "STRIDE_A must keep float4 alignment");
static_assert((STRIDE_B % 4u) == 0u, "STRIDE_B must keep float4 alignment");
If we pad the leading stride to 132 words and use that padded stride everywhere we touch sharedA (both when writing the transpose and when reading it later), the column now influences the bank. The two lanes that used to collide are split onto banks sixteen apart, and the four scalar stores for x, y, z, w rotate across banks rather than piling onto one. To prove this, I profiled the kernel after padding and the results showed store conflicts were eliminated.

Now we still have the actually bigger conflict which is the five-way bank conflict for the loads. The conflict mainly happens when loading from sharedB, particularly at:
for (int col = 0; col < COLS_PER_THREAD; col += 4) {
uint global_smem_col_idx = tx * COLS_PER_THREAD + col;
float4 temp_shared_B =
reinterpret_cast<float4*>(&sharedB[i * TILE_SIZE_K + global_smem_col_idx])[0];
reg_k[col + 0] = temp_shared_B.x;
reg_k[col + 1] = temp_shared_B.y;
reg_k[col + 2] = temp_shared_B.z;
reg_k[col + 3] = temp_shared_B.w;
}
For lanes 0..15, ty is still 0 but tx walks 0..15. If we freeze col = 0 to make it simple, the bank for the first word of each lane’s float4 will be:
- bank = (i* 128 + 8 * tx) % 32 = (8 * tx) % 32
- = 0, 8, 16, 24, 0, 8, 16, 24, ... only four banks used by a half warp
Now remember we are doing vectorised float4 loads so it spans four consecutive banks for that lane. So lane with bank start 0 touches banks {0,1,2,3}, lane with 8 touches {8,9,10,11}, lane with 16 touches {16,17,18,19}, lane with 24 touches {24,25,26,27}, and so on.
Since the pattern repeats every four lanes, that means we have four lanes that all want banks {0..3} at the same time, four lanes that all want {8..11}, etc. This is where we get a four-way conflict for this instruction.
For sharedA loads it’s different. What varies across lanes inside a half warp is tx, but tx does not appear in the address. Inside one half warp ty is constant. For fixed i and row, every lane computes the same address. So all sixteen lanes in the half warp read the same four words of sharedA at that step. As I said earlier this can be broadcasted, so it’s conflict-free in terms of load.
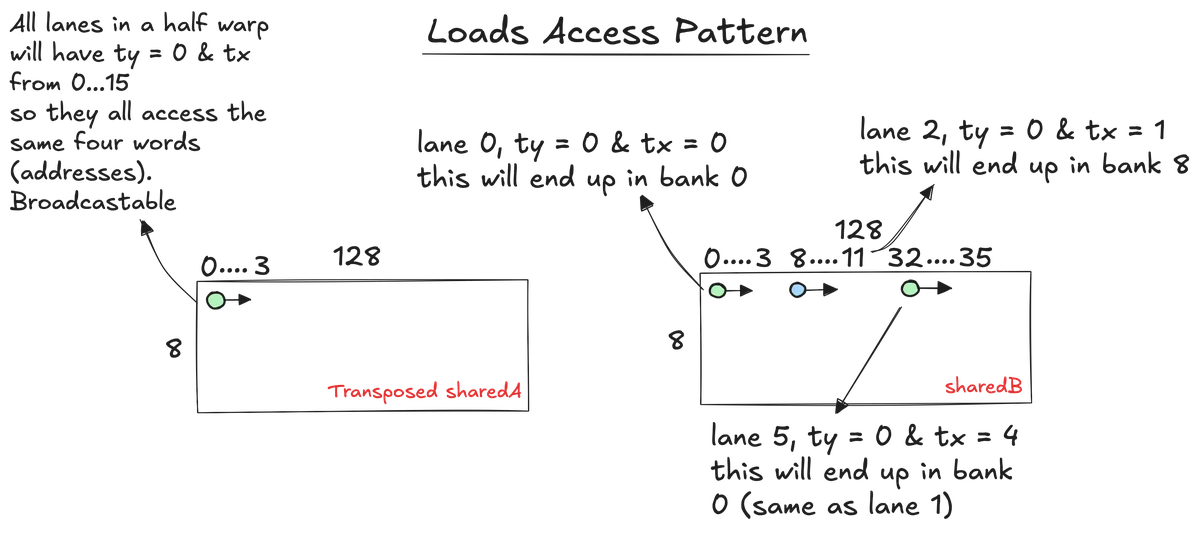
The important bit here is that padding does not fix this load conflict. Padding helps when the varying part of the address is multiplied by a stride that is a multiple of thirty-two words. In the sharedB load above, the varying part is tx * COLS_PER_THREAD + col, and that bit is not multiplied by the padded stride. So even if we set STRIDE_B = 132, the lanes inside a half warp still bunch onto the same four bank groups. So, padding solved the store side, but the sharedB load conflicts need a different approach.
Kernel 7: Warp Tiling
So far we exploited two levels of parallelism.
- Block tiling: Each thread block computed a large tile of the output matrix C, reusing tiles of A and B from shared memory.
- Register tiling: Each thread computed a small sub-tile of C (ROWS_PER_THREAD × COLS_PER_THREAD) entirely in registers, maximising data reuse before writing results back to global memory.
For this kernel, we will introduce a new level of tiling between block tiling and thread tiling and that is warp tiling.
Warp tiling sits between block tiling and thread tiling in the optimisation hierarchy. Instead of having all threads in a block cooperatively work on one large tile, we partition that tile into smaller sub-tiles, each assigned to a warp. This turns the warp into the middle-level unit of computation. The block still covers a 128 × 128 patch of C, but we split it into four 64 × 64 sub-tiles. Two warps along M by two warps along K which give us four warps per block.
TILE_SIZE_M = 128
TILE_SIZE_N = 16
TILE_SIZE_K = 128
WARP_TILE_M = 64
WARP_TILE_K = 64
WARP_STEPS_K = 4
ROWS_PER_THREAD = 8
COLS_PER_THREAD = 4
NUM_THREADS = 128 // four warps per block
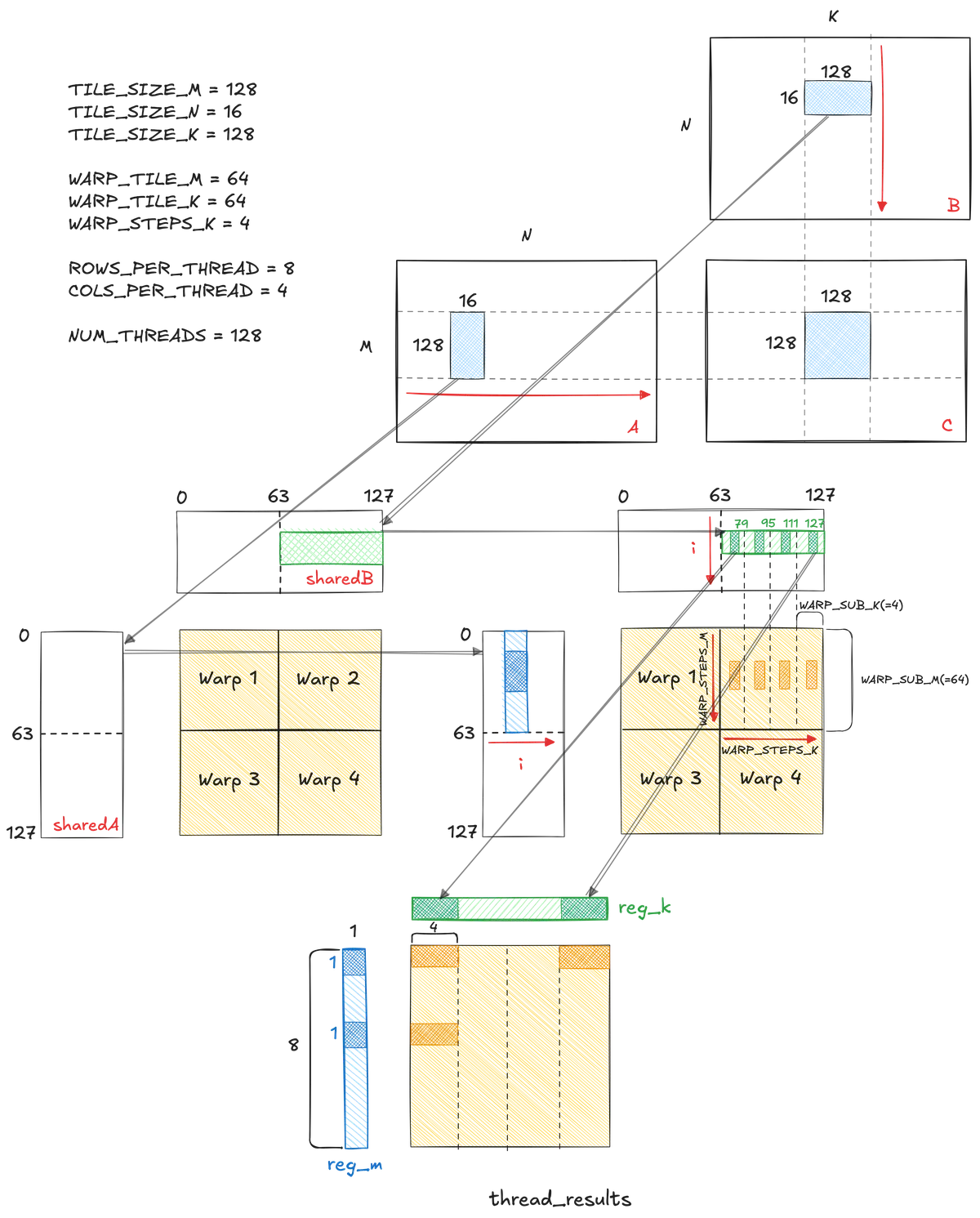
This extra level of tiling provides several benefits:
Alignment with hardware scheduling:
The warp is the fundamental execution unit in NVIDIA GPUs. By giving each warp its own sub-tile of the output, we align our work partitioning with the way the hardware actually schedules instructions.
By doing so, each warp can execute independently. If one warp stalls on memory, others can continue executing, which keeps warp scheduler slots full and reduces idle cycles.
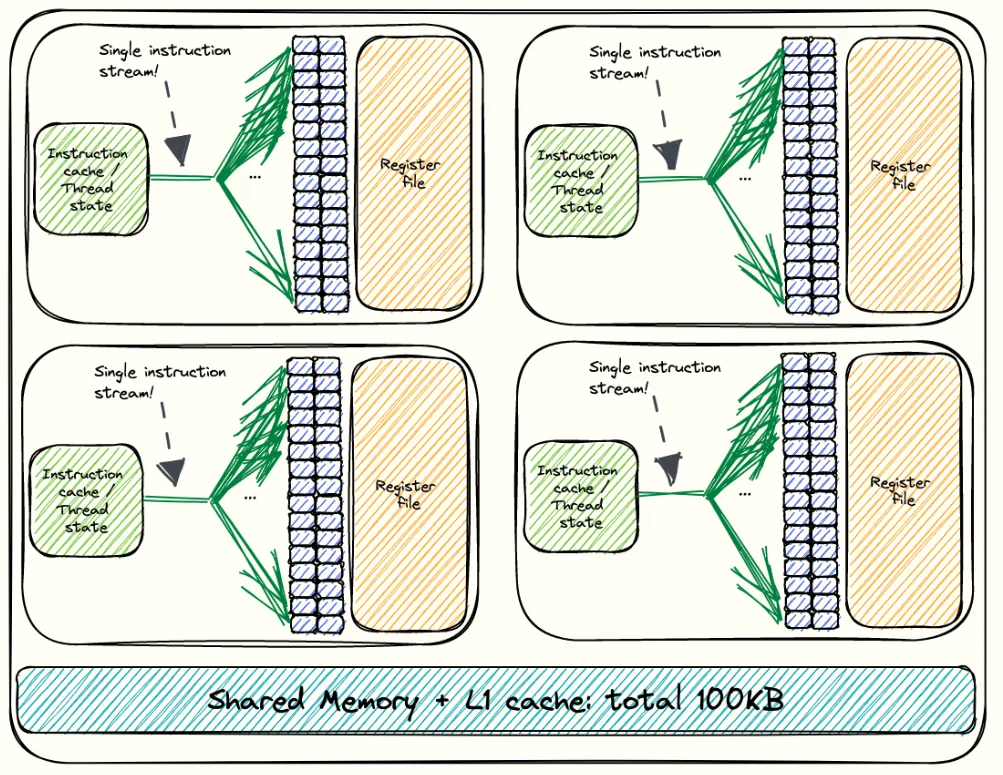 From Simon's blog
From Simon's blog
Control over shared memory access
Warp tiles keep each warp’s footprint compact and the per-lane strides simple and repeatable. That makes it easier to design bank-friendly layouts. Spoiler alert! that’s why SMEM load conflicts didn’t show up for this kernel.
Improved register cache locality
The register file (RF) inside each Streaming Multiprocessor stores per-thread variables. On Hopper, it’s split into multiple single-ported banks (similar to SMEM banks!). A bank can only serve one access per cycle. If two threads in the same warp try to read from the same bank in the same cycle, the accesses are serialized. This is called a bank conflict as well but for registers and it increases the time it takes to fetch operands for an instruction. Unfortunately NVIDIA’s profiling tools don’t provide metrics for these conflicts so it is hard to verify whether that was something we actually improved in this kernel.
Between the RF and the execution units are Operand Collector Units (OCUs) Paper: BOW Breathing Operand Windows to Exploit Bypassing in GPUs . Each OCU fetches source operands from the register banks and stores them in a small buffer, with space for three 128-byte entries. If an operand is needed again soon, it can be served directly from this buffer instead of going back to the main RF. This avoids both bank conflicts and extra RF traffic.
Warp tiling helps here because each warp works on a small, fixed sub-tile of the output matrix, so it tends to reuse the same registers repeatedly in the inner loop. This makes bank conflicts less likely and increases the chances that operands can be reused directly from the OCU buffer.
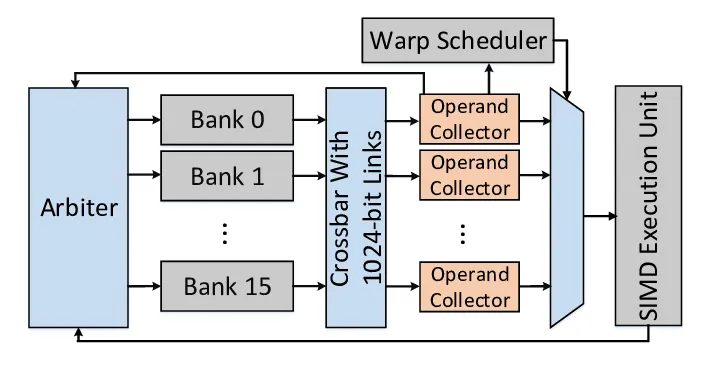
Again this is a speculation, Idk really if it makes a difference, but it seems plausible.
The main parts of the code that changed looks like this:
// Iterate over the shared dimension of the SMEM tiles
for (int i = 0; i < TILE_SIZE_N; i++) {
// Load slice at current i iteration in sharedA's register
for (int wSubRow = 0; wSubRow < WARP_STEPS_M; wSubRow++) {
uint base_row = (warp_row * WARP_TILE_M) +
(wSubRow * WARP_SUB_M) +
(ty * ROWS_PER_THREAD);
// Each thread loads ROWS_PER_THREAD into the register
#pragma unroll
for (int row = 0; row < ROWS_PER_THREAD; row += 4) {
const float2 va =
reinterpret_cast<float2*>(&sharedA[i * TILE_SIZE_M + base_row + row])[0];
__nv_bfloat16 t4[4];
memcpy(&t4[0], &va, sizeof(__nv_bfloat16) * 4);
reg_m[wSubRow * ROWS_PER_THREAD + row + 0] = t4[0];
reg_m[wSubRow * ROWS_PER_THREAD + row + 1] = t4[1];
reg_m[wSubRow * ROWS_PER_THREAD + row + 2] = t4[2];
reg_m[wSubRow * ROWS_PER_THREAD + row + 3] = t4[3];
}
for (int wSubCol = 0; wSubCol < WARP_STEPS_K; wSubCol++) {
uint col_base = (warp_col * WARP_TILE_K) +
(wSubCol * WARP_SUB_K) +
(tx * COLS_PER_THREAD);
// Each thread loads COLS_PER_THREAD into the register x4 (WARP_STEPS_K = 4)
#pragma unroll
for (int col = 0; col < COLS_PER_THREAD; col += 4) {
const float2 vb =
reinterpret_cast<float2*>(&sharedB[i * TILE_SIZE_K + col_base + col])[0];
__nv_bfloat16 t4[4];
memcpy(&t4[0], &vb, sizeof(__nv_bfloat16) * 4);
reg_k[wSubCol * COLS_PER_THREAD + col + 0] = t4[0];
reg_k[wSubCol * COLS_PER_THREAD + col + 1] = t4[1];
reg_k[wSubCol * COLS_PER_THREAD + col + 2] = t4[2];
reg_k[wSubCol * COLS_PER_THREAD + col + 3] = t4[3];
}
// Compute outer product producing (8*1) x (4*4) = 8x16
#pragma unroll
for (int im = 0; im < ROWS_PER_THREAD; im++) {
float a_val = __bfloat162float(reg_m[wSubRow * ROWS_PER_THREAD + im]);
#pragma unroll
for (int ik = 0; ik < COLS_PER_THREAD; ik++) {
float b_val = __bfloat162float(reg_k[wSubCol * COLS_PER_THREAD + ik]);
// Flatten (row, col) into thread_results
// row_index = wSubRow * ROWS_PER_THREAD + im
// col_index = wSubCol * COLS_PER_THREAD + ik
// row_stride = WARP_STEPS_K * COLS_PER_THREAD
int out_idx = (wSubRow * ROWS_PER_THREAD + im) *
(WARP_STEPS_K * COLS_PER_THREAD) +
(wSubCol * COLS_PER_THREAD + ik);
thread_results[out_idx] += a_val * b_val;
}
}
}
}
}
__syncthreads();
I tested out this kernel before and after padding:
Unpadded warp tiling
- Compute: SM busy 74%, FMA the top pipe (64% of active cycles), executed IPC ~2.97.
- Memory: ~372 GB/s, L1/TEX hit ~4.3%, Mem Busy ~55%.
- Conflicts: Shared stores reported ~4-way average bank conflicts; shared loads were not flagged.
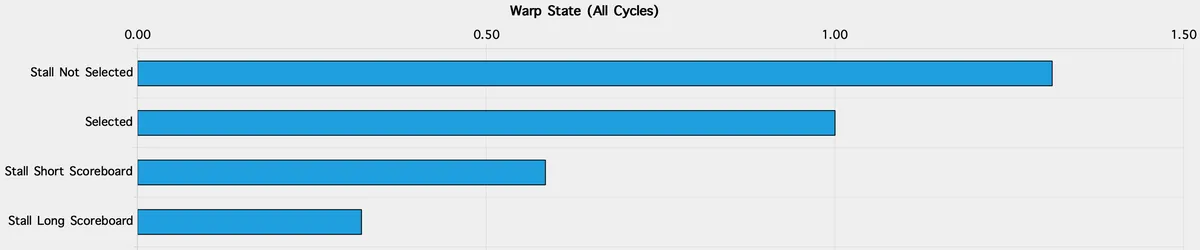
- Pressure/occupancy: ~165 registers per thread → achieved occupancy 18%; scheduler shows alot of “not selected” gaps (33% of inter-issue cycles).
Padded warp tiling
- Compute: SM busy ~75–76%, executed IPC ~3.03–3.04 (slight uptick).
- Memory: ~394–396 GB/s, L1/TEX hit rises to ~7–9%, Mem Busy ~52%.
- Conflicts: Shared stores drop to ~2.5-way on average. Shared loads still not flagged.
- Pressure/occupancy: ~167 registers/thread, achieved occupancy still 18%; “not selected” stalls remain a noticeable slice (31%).
So as a recap. In this warp-tiling kernel, padding mainly helped the store path (the transpose writes into sharedA), which matches the store-conflict counters dropping from about 4.0 to roughly 2.5-way. Load conflicts were not the issue here, unlike the earlier vectorised kernel. Two things quietly helped on the load side without us doing anything fancy: we use COLS_PER_THREAD = 4, which spreads sharedB lanes across more bank groups, and the warp-local sub-tile keeps lane patterns less aliasy. Together that’s why the profiler did not flag shared-load conflicts in either the unpadded or padded runs.
What still holds us back is elsewhere. Register pressure keeps achieved occupancy around ~18%, which shows up as “not selected” scheduler stalls. And we’re still broadly compute-bound (FMA busy in the high-60s) with memory ~52%, so squeezing a few extra GB/s won’t move the needle as much as overlapping copies with compute or trimming registers to buy another resident warp. This is also a good point to reach out for Hopper’s new TMA (Tensor Memory Accelerator), which is a hardware unit that moves 2D/3D tiles directly between GMEM and SMEM asynchronously. That lets us stream tiles in while we compute.