AWQ: Activation-Aware Weight Quantisation
Large Language Models (LLMs) have been a critical point in the advancement of the field of AI, arguably the greatest technological innovation in the last decade (Update: In NLP). These models, however, come with a sheer amount of model size, weights casually in the billions. As such, it’s become the default to run inference in the cloud, where serving providers have datacentres and GPU clusters that can handle such massive models.
While cloud-based deployment has traditionally supported the heavy computational demands of LLMs, there is a growing need to bring these models to resource-constrained edge devices. Why? Not all environments have stable internet access, so edge inference allows LLM-powered features to function offline. It also reduces delays caused by round trips to the cloud, lowers cloud compute cost, and improves scalability: serving millions of concurrent users in the cloud requires massive clusters, but if each device runs its own inference, scaling happens “for free.” Finally, there are privacy benefits, since sensitive user data never has to leave the device.
Doing so however, comes with it own set of challenged given the model sizes. For example, Llama-3.1 70B has ≈70.6B parameters. In half precision (FP16 or BF16), that’s ≈141 GB of memory. A single H100 SXM GPU has only 80 GB, let alone an edge device.
Those numbers are for model weights only. At runtime, we also need memory for the KV cache, which can eat up a large chunk if not handled efficiently, plus space for workspace buffers. See my other blog post about paged KV caching for how serving systems optimise KV cache memory.
Quantisation offers a way forward. In 4-bit (INT4), the weights of Llama-3.1 70B take ~45 GB instead of 141 GB, which is a massive reduction. But this comes with a catch: simply rounding down weights into low-bit buckets can degrade model quality. This is where Post-Training Quantisation (PTQ) comes in, and more specifically, where methods like Activation-Aware Weight Quantisation (AWQ) push PTQ further to make LLMs practical on edge devices. In this blog, I am to go through the paper to understand the theory behind it and how it compares to other methods.
Post-Training Quantisation (PTQ)
In PTQ, we start with a pretrained model in high precision (typically FP16 or BF16, i.e. half precision) and try to make it smaller for deployment. The goals can be summed up as:
- Smaller model: reduce the memory footprint so it can fit on resource-constrained devices.
- Faster inference: the quantised model should deliver predictions faster than the original, not just be smaller.
- Low cost to apply: PTQ is attractive because it doesn’t require retraining the model from scratch unlike Quantisation-Aware Training (QAT), which is slow and expensive. If you spend huge compute and time retraining during quantisation, it stops being PTQ and starts looking more like QAT.
AWQ is one such PTQ method. More specifically, it is weight-only quantisation: the weights are compressed to 4-bit while the activations remain in half-precision. This balance allows for massive memory savings while keeping accuracy competitive.
I think it’s important to understand the trade-offs between weight-only quantisation and weight + activation quantisation methods, since it’s natural to ask why the authors opted to quantise only the weights (the same is true for GPTQ). So let’s see the difference.
Weight vs Activation Quantisation
Weight-only quantisation is especially important when you are memory-bound. In these cases, the main limitation isn’t raw compute power but the sheer size of the model. The massive weight matrices dominate GPU memory usage and bandwidth, which means model size itself often bottlenecks generation speed, increases latency, and even prevents models from fitting on memory-constrained devices. By shrinking the weights, weight-only quantisation directly alleviates this bottleneck.
Activation quantisation, on the other hand, doesn’t reduce model size much but it can unlock faster use of hardware. If you quantise both weights and activations to a low precision (say 4-bit), you can run multiplications directly on INT4 tensor cores, achieving much higher throughput in terms of FLOPs. The catch is that activations are generated on the fly at inference time, so you don’t get the luxury of careful calibration like you do with weights. In practice, this usually forces naïve rounding, which makes it harder to preserve accuracy.
For the method we’re discussing, concerned with running LLMs on edge devices, most edge hardware doesn’t yet expose INT4 for activations as a first-class path. Edge chips typically support low-bit paths for weights, but not always for activations. For example, Apple’s A17 Pro and M4 chips support INT4 for weights but only allow activations in INT8. Similarly, NVIDIA’s TensorRT stack supports INT8 for activations, while INT4 is reserved mainly for weights. Combined with the fact that the main concern on edge is fitting large models into limited device memory, it makes sense that AWQ focuses specifically on weight-only quantisation.
What about the KV cache?
A natural follow-up question after discussing weights and activations is: what about the KV cache? The KV cache is technically part of the activations and, at long context lengths, it quickly becomes one of the largest memory consumers. So why does AWQ ignore activations if the cache itself is an activation?
The reason is that KV cache quantisation is generally treated as a "separate knob" in serving systems, distinct from both weight quantisation and activation quantisation in the forward pass. For example, in vLLM you can set the kv_cache_dtype flag to fp8, regardless of whether your model weights are in FP16 or INT4. This way, you can compress the weights to INT4 with AWQ and independently shrink the KV cache by storing it in FP8. Since the cache grows linearly with sequence length and batch size, this knob is one of the most effective ways to scale to longer contexts efficiently.
Quantisation Granularity
When quantising a tensor, its elements can be partitioned into groups, with each group sharing the same quantisation scale and zero-point. This approach is known as group-wise quantisation. The choice of group size introduces a trade-off: larger groups reduce the amount of metadata required but risk lower accuracy, while smaller groups increase metadata but allow finer precision.
The simplest case is per-tensor quantisation. In this scheme, a single scale factor and zero-point are computed for the entire tensor. For example, if we take the weight matrix of a linear layer, the global minimum and maximum values across all weights determine one pair of parameters applied uniformly to every element.
A more fine-grained strategy is per-channel quantisation. Here, each channel of the tensor is treated as a separate group, with its own pair. In the case of a linear layer with a weight tensor shaped as [output_features, input_features], this typically means each output feature (row) receives its own quantisation parameters. This preserves more accuracy compared to per-tensor quantisation, especially when different channels have very different value distributions.
Pushing granularity even further, we arrive at per-group quantisation. Instead of assigning one group per channel, each channel can be subdivided into smaller groups. Each group then has its own independent parameters. In practice, grouping is often applied along the input_features dimension. Typical group sizes are 32, 64, or 128.
For example, if a weight matrix has shape [output_features, 1024] and the chosen group size is 128, then each output channel’s weight vector (length 1024) is split into 8 groups (1024 ÷ 128 = 8). Each of those groups would then be quantised separately, giving 8 distinct pairs per output channel.
📝 The quantisation scale I referred to up until now as in the paper is denoted as . You will find that I use and interchangeably here in this blog, but essentially they mean the same thing.

AWQ: Activation-Aware Weight Quantisation
Group-Wise Weight Only Quantisation
In a simple linear layer, PyTorch’s nn.Linear computes:
where is the weight matrix and is the input activation vector.
Under weight-only PTQ, we store a compressed, low-bit quantized version of (for example, in INT4 as used in this paper), but at inference time these integers are multiplied by their corresponding scale factors to recover their approximate floating-point values. The recovered matrix is referred to as the dequantized weights.
The actual computation therefore becomes:
This approach shrinks the model’s stored size, since the integers are tiny compared to floats and can fit in much more limited memory, while keeping the runtime arithmetic in standard floating-point form.
The type of quantisation used in this paper is symmetric quantisation, where zero in the original floating-point range maps directly to zero in the compressed integer range. The paper defines the dequantization function as:
Here, is the quantisation scale for that group, maps the scaled weight to the nearest integer (which is what we actually store in memory), and multiplying back by recovers a floating-point approximation of the original weight.
For the full derivation of how this formula is obtained, see the side note Quantisation Mapping: The main idea is that we want to take floats in some big range and squash them into integers in a smaller range . For signed INT8, for example, that range is . To make this work, we assume a straight-line relationship between the float and its quantised integer . For more detail checkout Lei Mao’s blog post where he goes in depth into this. It helped me understand this more clearly:
Here is the scale, i.e how many float units each integer step covers, and is just an offset. If we want to go the other way (float to integer), we flip the line and round:
The line has to hit the ends of both ranges, so we require:
Subtracting these two equations gives:
Using distributive law:
which means:
Once we know , we can plug it back into to get :
and replacing gives:
That’s the general form tho. In practice libraries usually call the scale and the zero point, and the final formulas you actually use look like this:
with
Let's run this through an example visually to map the concepts better assuming we having a vector of 5 weights that are represented in FP32 and we would want to quantise to int8.
In practice we do not map the entire precision range in FP32 for thats [-3.4e38, 3.4e38] into INT8. Instead, we take the actual data we want to store, find its minimum and maximum, and fit that interval into the INT8 code range.

Symmetric vs Asymmetric Quantisation:
Notice the difference. In asymmetric quantisation we use the true data range, so is the minimum of the tensor and is the maximum. That choice gives a non-zero 0 point in code space, which is why in the first example 0 in float was stored as the code . We also use the full set of INT8 codes end to end. In symmetric quantisation we centre the float range around 0 by taking to be the larger of the absolute min and max, then map the interval from to onto a perfectly centred code range with zero point .
. In that derivation I refer to the scale as , but it is equivalent to . I will continue to use here to stay consistent with the notation in the paper.
For symmetric quantisation we choose a single parameter to define the floating-point range we want to represent. Specifically, we pick
so that the floating-point range is
This guarantees that all the weights fit inside the representable range. We then map this continuous interval onto the discrete signed integer range
where is the bit-width (e.g. for INT4 or for INT8). The resulting quantisation scale is therefore
Intuitively, tells us how much real-valued change in the weights corresponds to a single integer step in the quantised representation. By centring the range at zero, we also make the zero point , which is why this approach is called symmetric quantisation. For INT4, as in our case, the representable quantised range is:
📝 Important Note: The range is the "restricted" range typically assumed for symmetric quantisation. The "unrestricted" signed INT4 range is . Most frameworks like TensorRT tend to use the unrestricted range, but I use the restricted version here to keep the symmetry around zero explicit.
To better understand what represents, let’s take an example where the maximum absolute value of a 1-D tensor is . The scale computed from our formula is approximately . This means that the mapping from integer codes to floating-point values is a straight line with slope . In other words, every step of 1 in the integer code corresponds to a change of about 1.43 in the floating-point value.
Analysing the Quantisation Error
In the quantisation process of weight-only quantisation, the only source of distortion comes from rounding. Since the quantisation range is chosen to fully cover the weight matrix, we’ve already fixed so there’s no clipping involved. Every weight is guaranteed to lie in the representable range, so we don’t lose information by cutting off extremes. The only loss comes from replacing each original weight with the nearest grid point defined by the step size .
The rounding error, based on our earlier definition of , is therefore
That is, it measures how far the dequantised value (the recovered float) deviates from the original floating-point weight. When these quantised weights are used inside a linear layer during inference, the output for some input activation vector (ignoring the bias for now) is approximated as:
Hence the error in the output (compared to using the original weights) is:
where
This shows two key observations about where the error comes from and how it propagates:
- The error is scaled by the step size
- The error is also scaled by the activation magnitude
Step Size Scaling
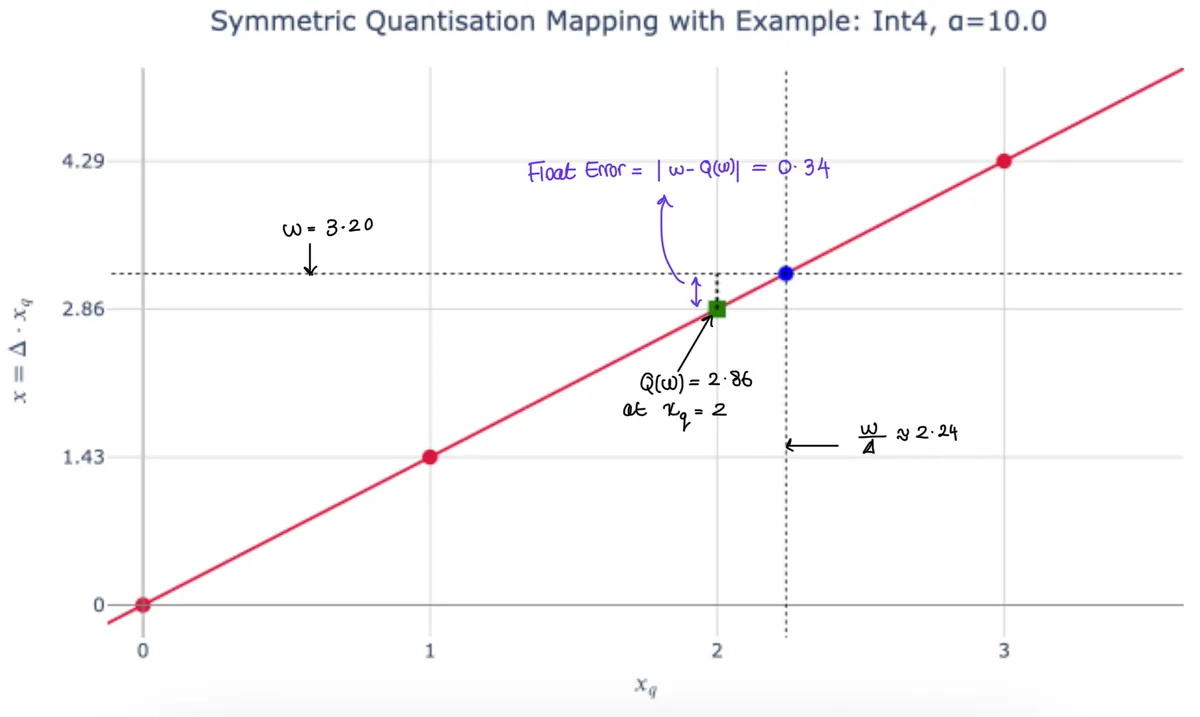
Let’s use an example for this: Suppose the quantisation step size is (Same as plot above) and we have a weight with value .
If we divide by to express this weight in terms of the quantisation grid, we get
This tells us the weight lies a little more than two steps along the integer grid.
However, the quantiser cannot store the fractional part 0.24 as it can only keep the nearest integer code, which in this case is 2.
When we convert back to float space, the recovered (dequantised) weight is
The original weight was , so the rounding mismatch in float space is
The key insight is that the rounding happened in the scaled grid domain as we lost a fractional 0.24 step. But in the original float space, each grid step is worth , so that fractional 0.24 step translates into an actual error of
That’s why it's said the quantisation error is “scaled by ”. The size of the step determines how much any fractional misalignment in grid space costs you in real value. The larger the step size, the further apart neighbouring grid points are, so being off by a fraction of a step causes a bigger discrepancy in the recovered weight. The plot below demonstrates the example I've been going through.
📝 The plots are interactive so you can zoom into to see the float error.
I've also annotated it statically if you are interested.
Activation magnitude scaling
The formula for the output error includes a factor of which further scales the mismatch. This means the same rounding error in a weight will matter more when the corresponding activation is large, and much less when the activation is small.
Imagine for example we have two weights, and , that both suffer the same rounding error of after quantisation as in the previous example. The effect on the output will differ hugely based on their corresponding activations. If and :
- For , the error term is
- For , the error term is
So, in other words, the quantisation error that actually affects the network’s output isn’t just about how accurately you can store each weight; it’s about how much that weight is “used” by the input activations during inference.
Theoretical Note on Error Distribution and Activation-Awareness
The paper adds an interesting statistical observation. If you take a large collection of weights, their scaled versions tend to have fractional parts that are spread fairly evenly between 0 and 1. This means that the rounding errors, which arise when we round those fractional parts up or down to the nearest integer, are themselves uniformly distributed in the interval .
Since in practice we often care about the size of the error rather than its sign, it makes sense to think about the absolute value of the rounding error. Its magnitude lies in , and for a uniform distribution the average absolute error works out to about 0.25 steps.
So far we have talked about the general case, that in general the quantisation error depends on both the step size and the input activation. That statement holds true if every weight has its own scale, because then both factors vary across weights. However, in group-wise quantisation, which is what AWQ uses, all the weights within a group share the same scale . This means that within a group the expected rounding error is essentially fixed, so the quantisation error in the output is proportional only to the input activation.
This is the key reason the paper refers to weight-only quantisation as activation-aware. If the activations flowing into the group are small, the quantisation error barely affects the output. If the activations are large, the same grid misalignment produces a proportionally larger discrepancy in the output. Therefore, if we could reduce the input activation magnitude in weight-only-quantisation, the quantisation error can be reduced.
Scaling Weights and Activations
Consider the same linear layer we have been using so far
An intuitive idea to reduce the input activation magnitude is to scale the weights and inversely scale the activations. Let
where is a vector of per-channel scaling factors. Its diagonal matrix is
For a weight matrix
multiplying by scales each column:
so the column of is multiplied by . For an input activation
scaling by the inverse rescales the activations:
With this re-parameterisation the layer becomes
where the scaled weights are quantised as
and the quantisation step size is set by the maximum magnitude of the scaled weights:
In exact arithmetic this transformation does not change the computation, since
so we are only re-parameterising the layer. However, in quantised inference the rounding now acts on the scaled weights rather than on , and the quantiser’s grid is defined by the scaled magnitudes. As defined in the paper, the resulting output error is therefore
If moves closer to a quantiser grid point without increasing the group’s maximum (), the quantisation mismatch shrinks, and any remaining error is further reduced by the factor applied to the activation. Thus, scaling allows us to reduce the effective contribution of quantisation error from the channels where it matters most.
Optimising Scaling Factors
In the paper they don’t try to optimise directly with gradients. Instead, they narrow the problem down to a simple search space, guided by the earlier point that the “importance” of a weight channel really comes from the scale of the activations flowing through it.
They write the scaling vector as
where reflects how large each input channel typically is, and is just one scalar that decides how much extra scaling we give to the big-activation channels.
The optimisation then boils down to
Rather than training it, they just do a grid search over
- When there’s effectively no scaling.
- When you get the most aggressive scaling in this search space.
This simple setup avoids the instability of gradient-based methods and captures the key idea: channels that usually see bigger activations get scaled up more so their weights land closer to the quantiser’s grid points.
Conclusion
In summary, deploying LLMs on edge devices demands efficient compression without compromising accuracy. AWQ, a post-training group-wise weight-only quantisation technique, achieves lower quantisation error than vanilla approaches and has even outperformed more complex schemes like GPTQ, making it a practical and effective solution for running large models on memory-constrained hardware. In this blog, we explored how input activations influence quantisation errors in symmetric weight-only quantisation and demonstrated, through theoretical analysis, how making the process more activation-aware and scaling appropriately can further reduce these errors.